Vector Stores
This page is about Seekr Vector Stores.
Vector Stores Overview
Vector Stores in SeekrFlow are high-performance semantic indexes built from your documents. They allow language models to retrieve meaningful, contextually relevant information — powering workflows like agents, assistants, and context-grounded fine-tuning.
This page covers everything you need to know to create, configure, and manage Vector Stores.
🧠 What Is a Vector Store?
A Vector Store (also called a vector database or VectorDB) stores vector representations of your content — meaning each chunk of your documents is converted into an embedding, making it searchable by semantic similarity rather than just keywords.
Use a Vector Store when you want to:
- Enable semantic retrieval for Agents or Assistants
- Generate Context Grounded datasets for fine-tuning
- Create long-term memory systems from documentation or internal knowledge
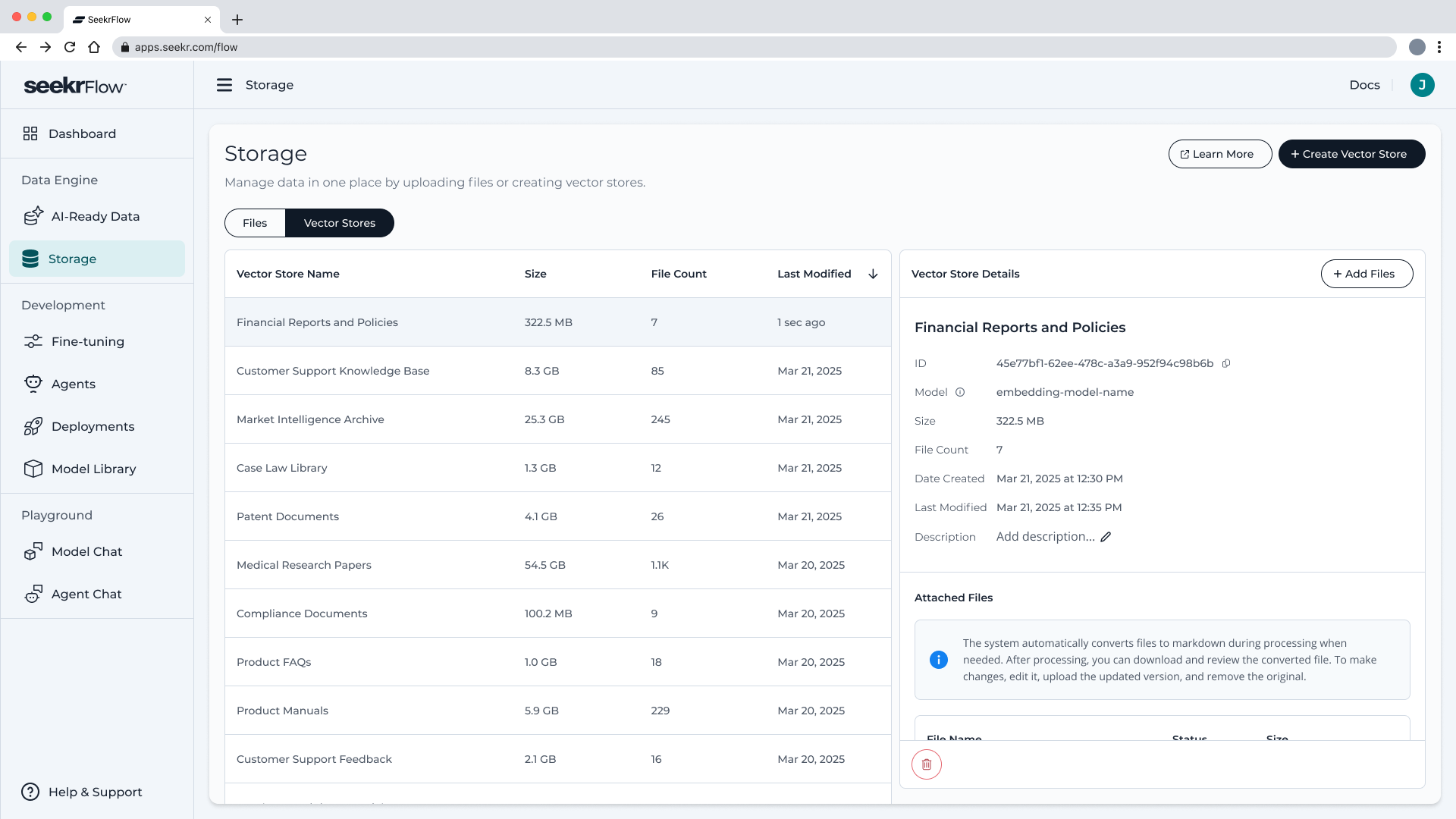
🛠 How to Create a Vector Store
- Navigate to Data Engine → Storage → Vector Stores
- Click Create Vector Store
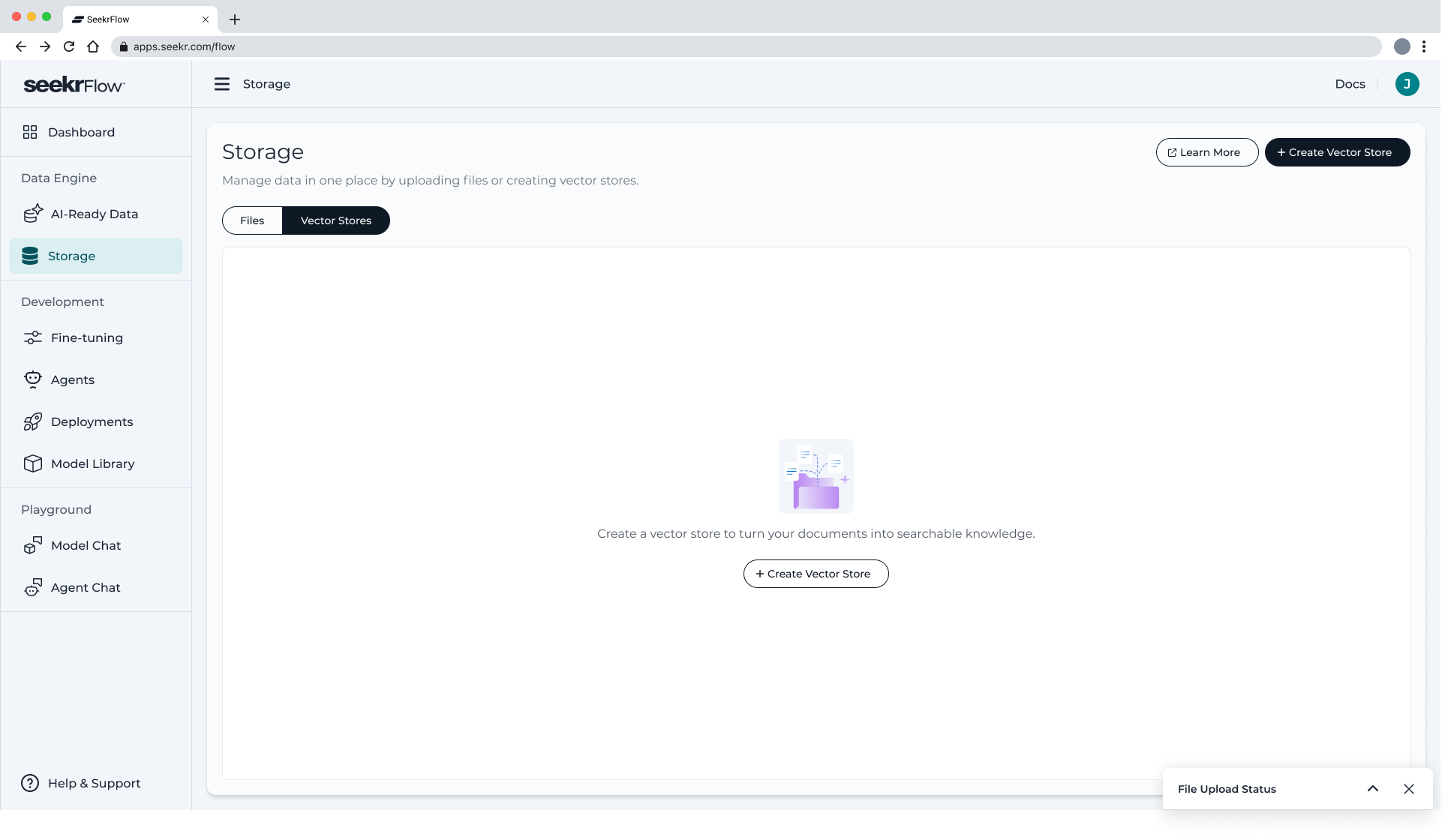
-
In the modal, enter:
- Vector Store Name (required)
- Description (optional)
- Embedding Model – select from available options
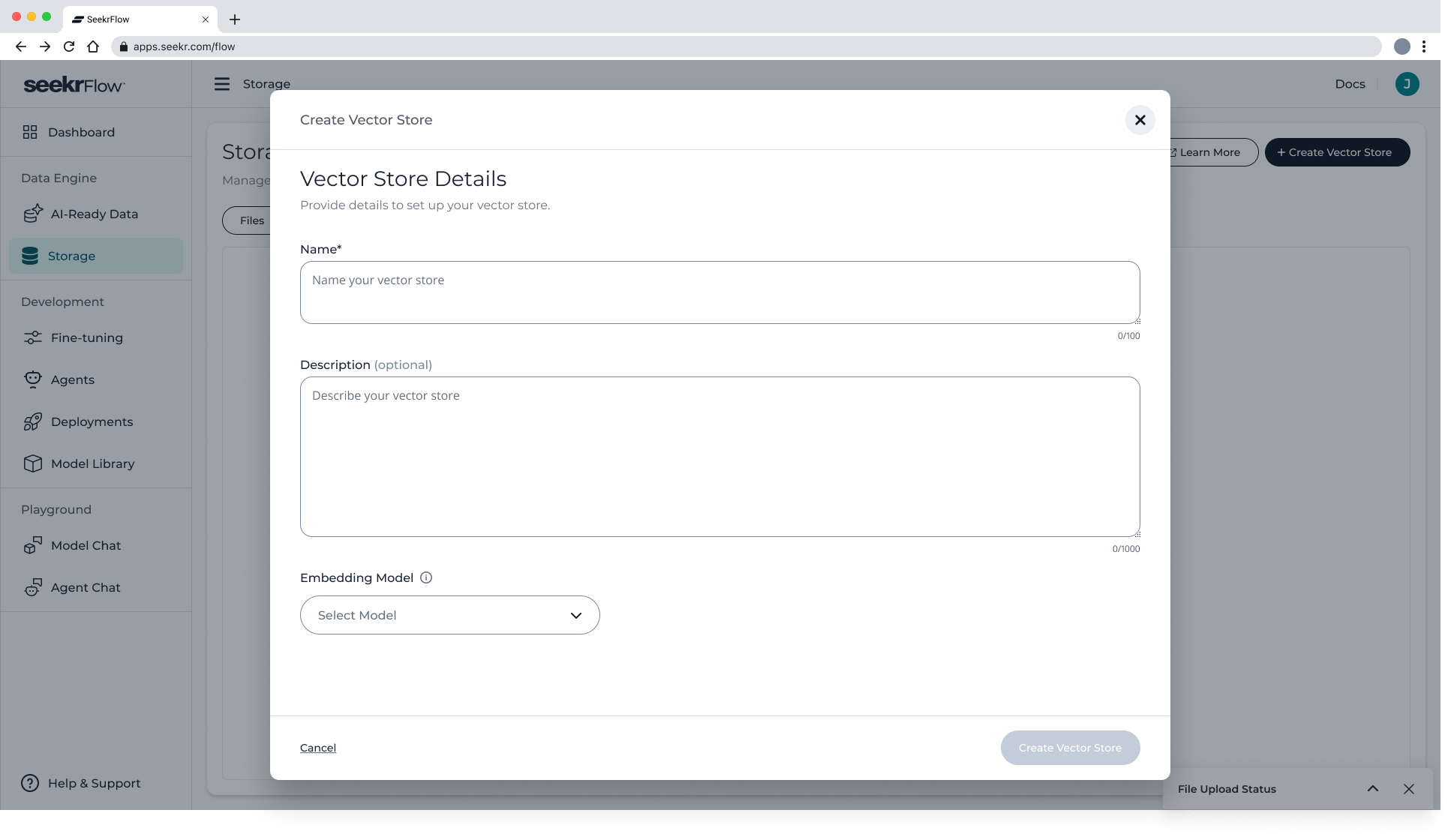
- Click Create Vector Store
You’ll return to the Vector Stores tab where your new store appears in the list with:
- Name
- File count
- Total size
- Date modified
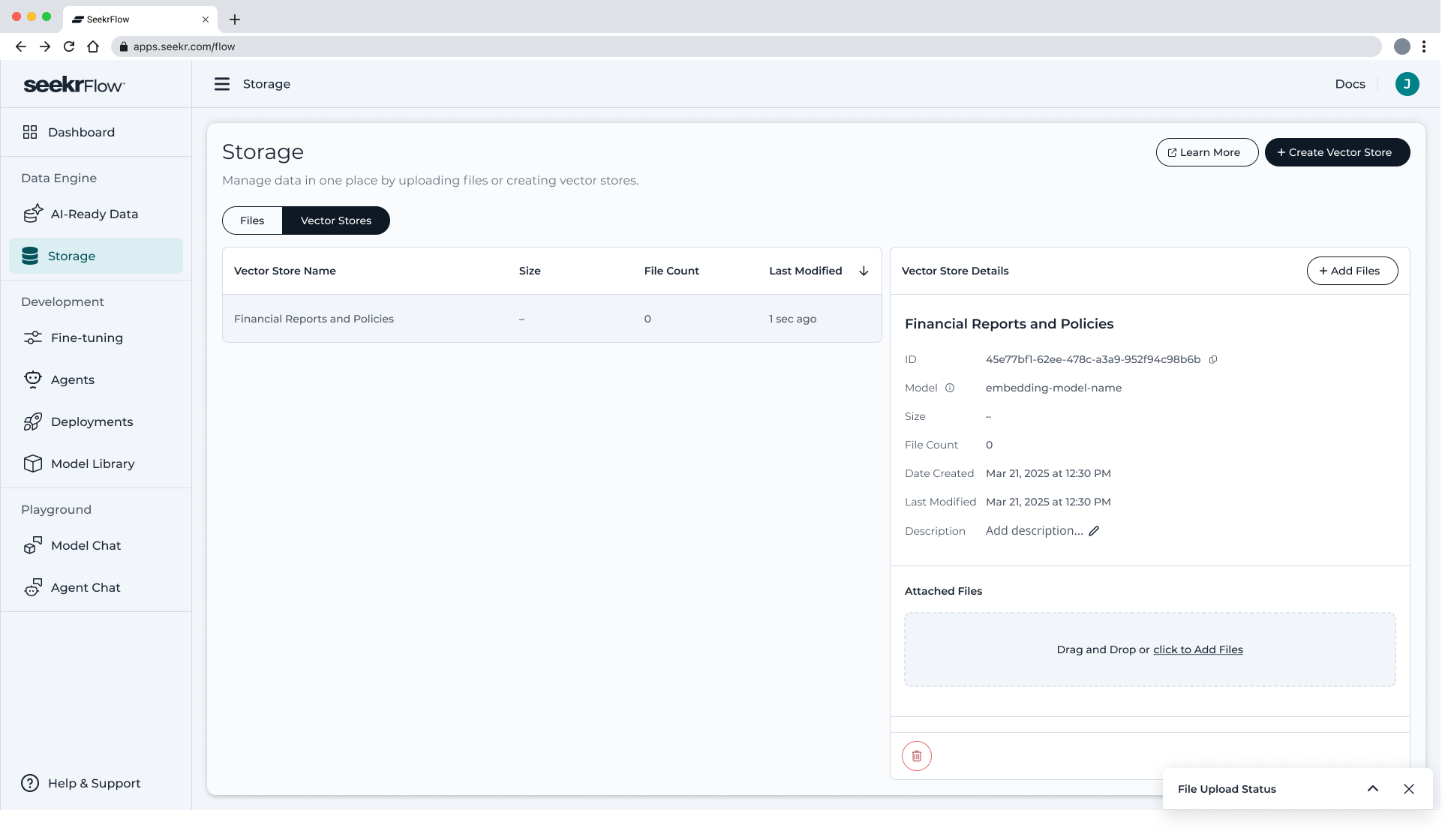
📋 Vector Store Details View
Click on any vector store to open the details view, which displays:
- Vector Store ID
- Selected embedding model
- Created at
- Description
- Section to Add Files to the store
- List of any existing embedded files
➕ Adding Files to a Vector Store
To attach documents to your store:
-
Click Add Files in the detail view
-
A modal will open, giving you two options:
- Select from existing files in File Storage
- Upload new files directly into this vector store
You can drag and drop or browse to upload.
Upload Limits:
-
Up to 20 files at a time
-
Maximum 150MB per file
-
Supported file types:
.pdf.docx.ppt.md.json
Unsupported files (like.jsonl,.parquet, or.txt) cannot be added to a vector store.
🔧 Chunking Settings
After selecting your files, configure how your content will be segmented:
-
Intelligent Chunking (default):
Automatically detects logical content breaks (e.g., headings, paragraphs) -
Manual override options:
- Chunk Size (token count)
- Chunk Overlap (token count)
This ensures precise control over how your data is broken down before embedding.
🚀 File Processing Flow
Once you click Add Files, SeekrFlow will handle everything automatically:
- Ingesting — Converts compatible files into Markdown if needed
- Chunking — Breaks content into manageable segments
- Embedding — Transforms each chunk into a high-dimensional vector
- Indexing — Stores vectors into the semantic index
You’ll return to the Vector Stores tab where file processing begins in real-time.
📂 File View in Vector Store
When processing completes, embedded files appear in the detail view with:
- File name
- Status (Queued, Ingesting, Chunking, Embedding, Complete)
- Size
If a file fails to process, you’ll receive an error with guidance for resolution.
🔄 Managing Your Vector Store
Inside the detail view, you can:
- Add or remove files
- Monitor file status
- Rebuild the store if content or structure changes
- Track where the vector store is being used (coming soon)
🔗 How Vector Stores Power SeekrFlow
Vector Stores connect directly into major workflows:
- Agents & Assistants — power retrieval-augmented memory
- Context Grounded AI-Ready Data Jobs — generate training data from retrieved chunks
- Fine-Tuning — use structured content to improve model alignment
Each store is fully reusable and optimized for high-performance semantic access.
Updated about 2 months ago