File Storage
This page is about Seekr File Storage.
File Storage Overview
The File Storage tab in SeekrFlow is where you upload, manage, and inspect all the source documents used throughout the platform. Whether you're preparing training data, building vector stores, or grounding agents — everything starts with your files here.
This page covers how to upload files, what file types are supported, how file management works, and how downstream workflows generate new files within your storage.
File formatting guidelines
Before uploading, make sure your files are properly formatted by following these steps:
PDF and DOCX:
- Use clear headings and avoid images without context.
- Ensure text content is structured logically for conversion.
Markdown:
- Use correct header hierarchy (
#H1, ##H2, ##H3,etc.). - Limit headers to six levels (
######). - There's a clear, logical flow of information throughout.
- Avoid missing or empty headers and skipped levels.
- Ensure all sections have meaningful content under them.
Note: Google Docs users can export files as Markdown, PDF, or DOCX.
JSON
- When creating JSON files for ingestion, the structure must follow a tree-like format with specific fields. Each node represents a section of content and may contain nested child sections.
- Required Fields
-
labelA short title or question for this section. Example:"Title heading for this section" -
contentThe main body text associated with this section. Example:"This document describes..." -
childrenAn array of child objects. Each child has the same structure (label,content,children,level).- Use an empty array (
[]) if there are no children.
- Use an empty array (
-
levelA string representing the depth of the section in the hierarchy."0"= root"1"= first-level child"2"= second-level child, and so on.
- Rules & Guidelines
- Always include all four keys (
label,content,children,level) in every object. - Nest sections inside
childrento create hierarchy. levelshould always match the depth of the object within the tree.- Use plain text or markdown in
content(bullets, emphasis, etc. are supported). - Keep
childrenin an array, even if it’s empty.
Example:
{
"label": "Seekr Ingestion Rules",
"content": "This document explains seekr ingestion...",
"children": [
{
"label": "JSON Example",
"content": "You can upload json files...",
"children": [],
"level": "1"
}
],
"level": "0"
}🚫 Upload Limits
-
Max files per upload: 20
-
Max file size: 150MB per file
-
Supported file types:
.pdf.docx.ppt.md.json.jsonl.parquet
Files in unsupported formats or exceeding size limits will be rejected with an error.
📥 Uploading Files
To upload files:
- Go to Data Engine → Storage → File Storage
- Click Upload Files
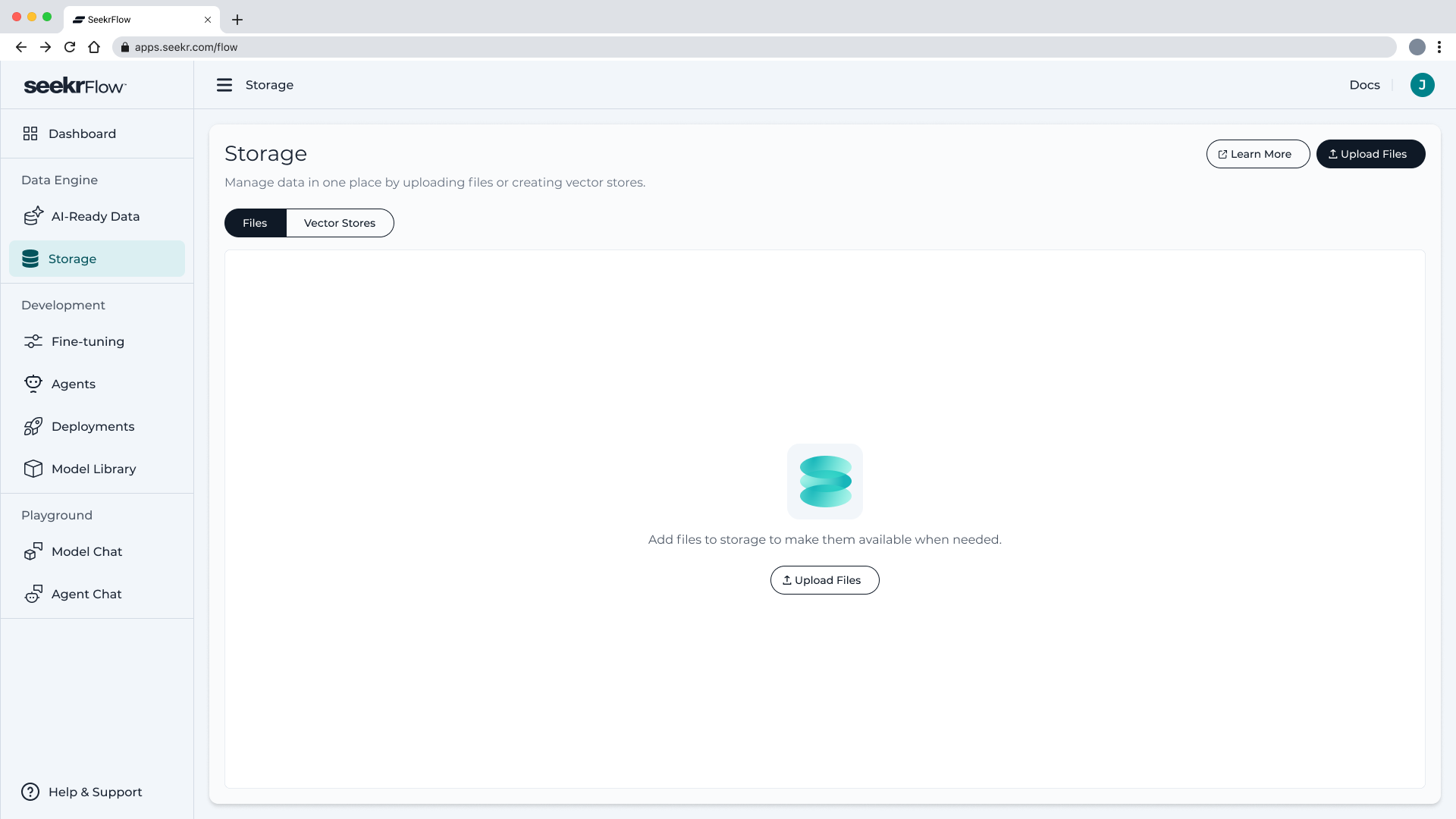
- In the modal that appears, drag and drop your files or browse your device
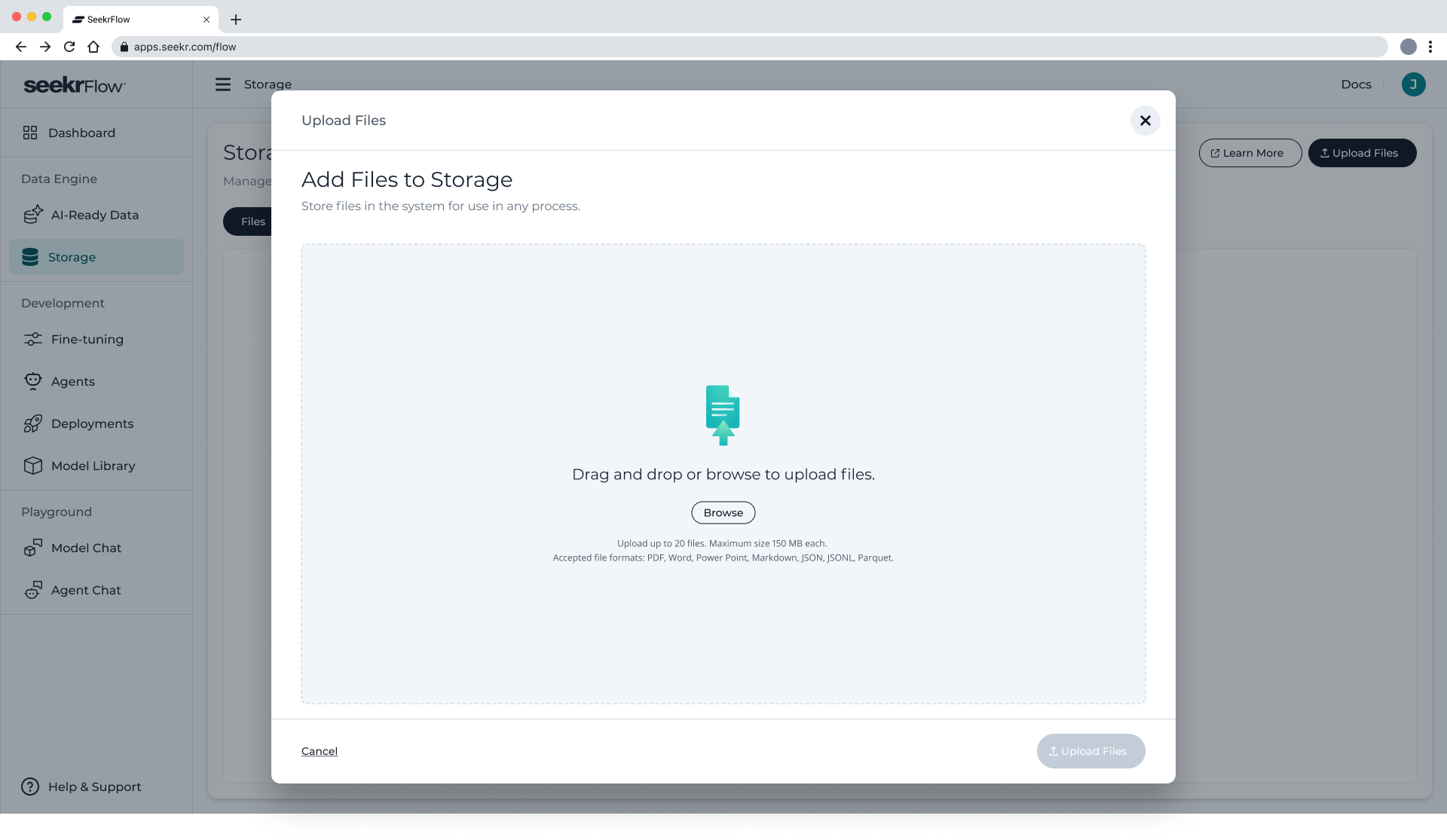
- SeekrFlow will validate the files and show any issues

- Click Upload Files to confirm and start the upload
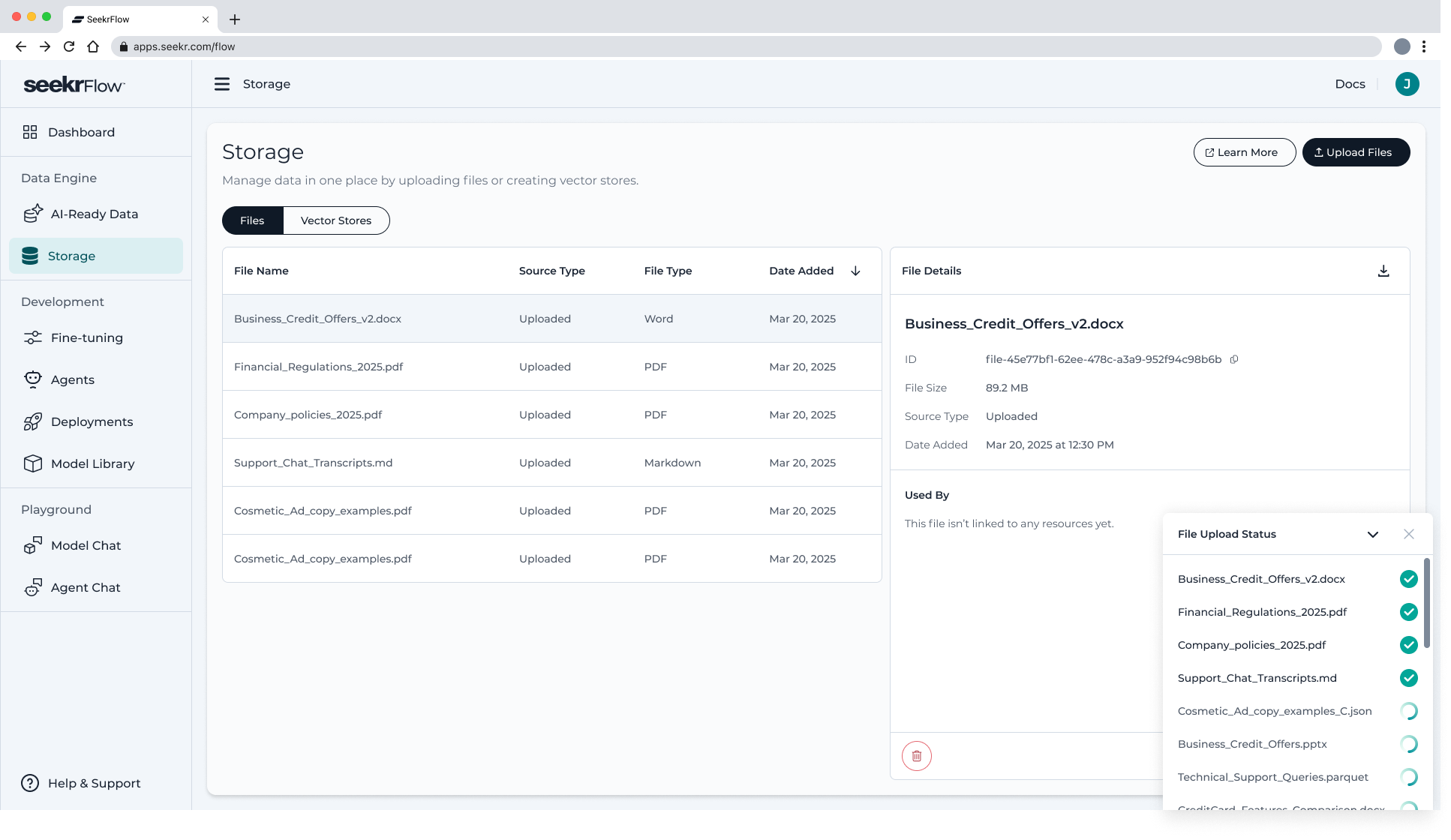
You’ll return to the Files tab where your uploads begin immediately and appear in the list view.
🔄 What Happens After Upload?
Uploaded files are stored in your SeekrFlow workspace and become available for use across the platform. No processing or ingestion occurs in the File Storage tab itself — ingestion only happens once files are selected within downstream workflows like AI-Ready Data or Vector Stores.
📁 Ingestion + File Generation Behavior
SeekrFlow may add new files to your File Storage automatically as a result of downstream processing. Here’s how:
-
Ingested Files → Converted Markdown (.md): If you use a
.pdf,.docx, or.pptfile in a workflow that requires ingestion (e.g., AI-Ready Data or Vector Stores), SeekrFlow will create a new.mdfile representing the converted output.- File name: same as the original, but with a
.mdextension - Source type:
Converted
- File name: same as the original, but with a
-
Parquet QA Pairs → Generated Output: When you complete a Standard Instruction (Principle Alignment) job, the system generates a
.parquetfile containing your Q&A pairs. This file will automatically appear in your File Storage.- File name: generated based on your job
- Source type:
Generated
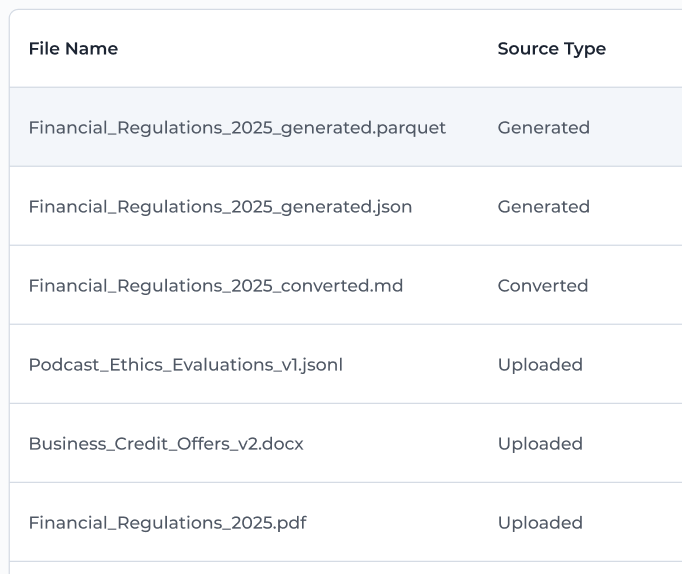
These files behave like any other file — you can use them in future jobs, vector stores, or fine-tuning workflows.
🔁 Where Files Are Used
Files in your storage can be selected and reused across key workflows:
- AI-Ready Data Jobs — generate structured datasets for fine-tuning
- Vector Stores — enable semantic search and context grounding
- Fine-Tuning — train custom models using structured Parquet data
- Agents & Assistants — allow models to retrieve grounded content
All files are traceable, inspectable, and cross-compatible with SeekrFlow’s end-to-end pipeline.
📋 File List View
The File Storage list includes:
-
File name
-
Source – shows how the file entered the system:
Uploaded— uploaded manually by the userConverted— created via ingestionGenerated— created by a SeekrFlow process (e.g., alignment/parquet output)
-
File type
-
Date added
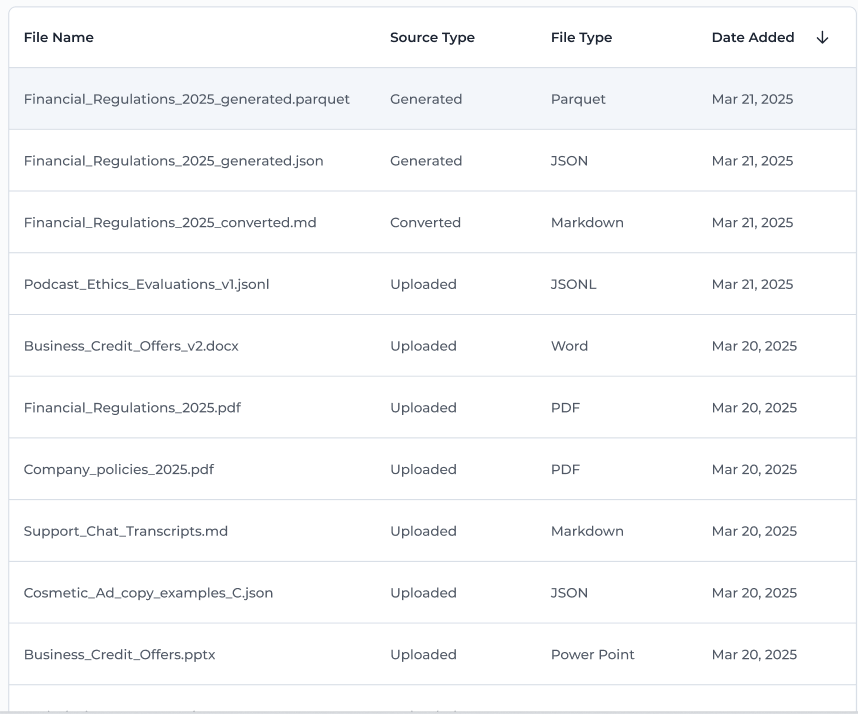
This gives you a clear overview of your file inventory and how each item came into your workspace.
🔍 File Details Panel
Click on any file to open its details view, showing:
- File ID
- File size
- Source type
- Date added
- Used By — lists all workflows where the file has been used (e.g., AI-Ready Job, Vector Store, Fine-Tuning)
- Delete button — remove file if not actively used elsewhere
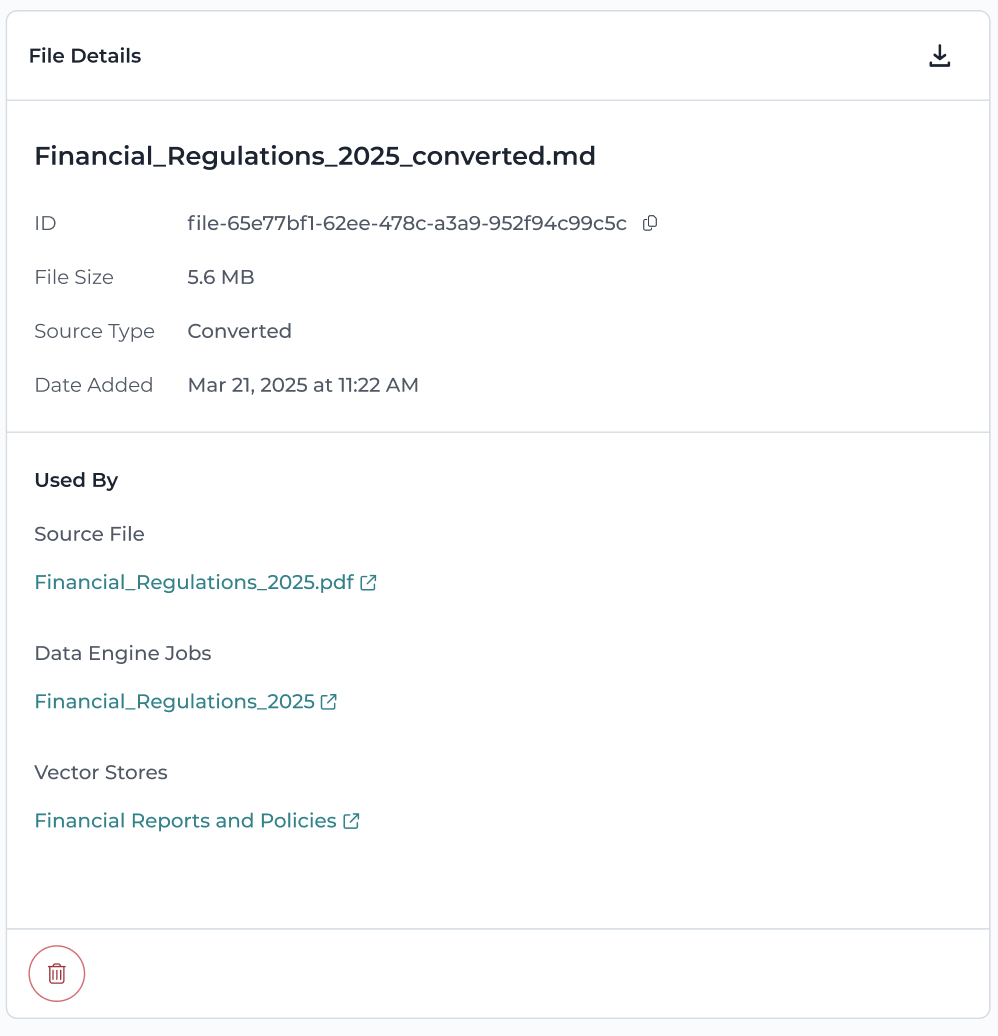
🧠 Tips for File Management
- Upload files with clear names for easier traceability
- Expect
.mdfiles to be created automatically from PDFs, DOCX, or PPTs during ingestion - Reuse generated
.parquetfiles for fine-tuning without reprocessing original documents - Use the Source column to quickly identify what’s user-uploaded vs system-generated
Updated about 2 months ago