> ## Documentation Index
> Fetch the complete documentation index at: https://docs.seekr.com/llms.txt
> Use this file to discover all available pages before exploring further.
# AI-Ready Data
> Generate training data from your unstructured documents to fine-tune a model.
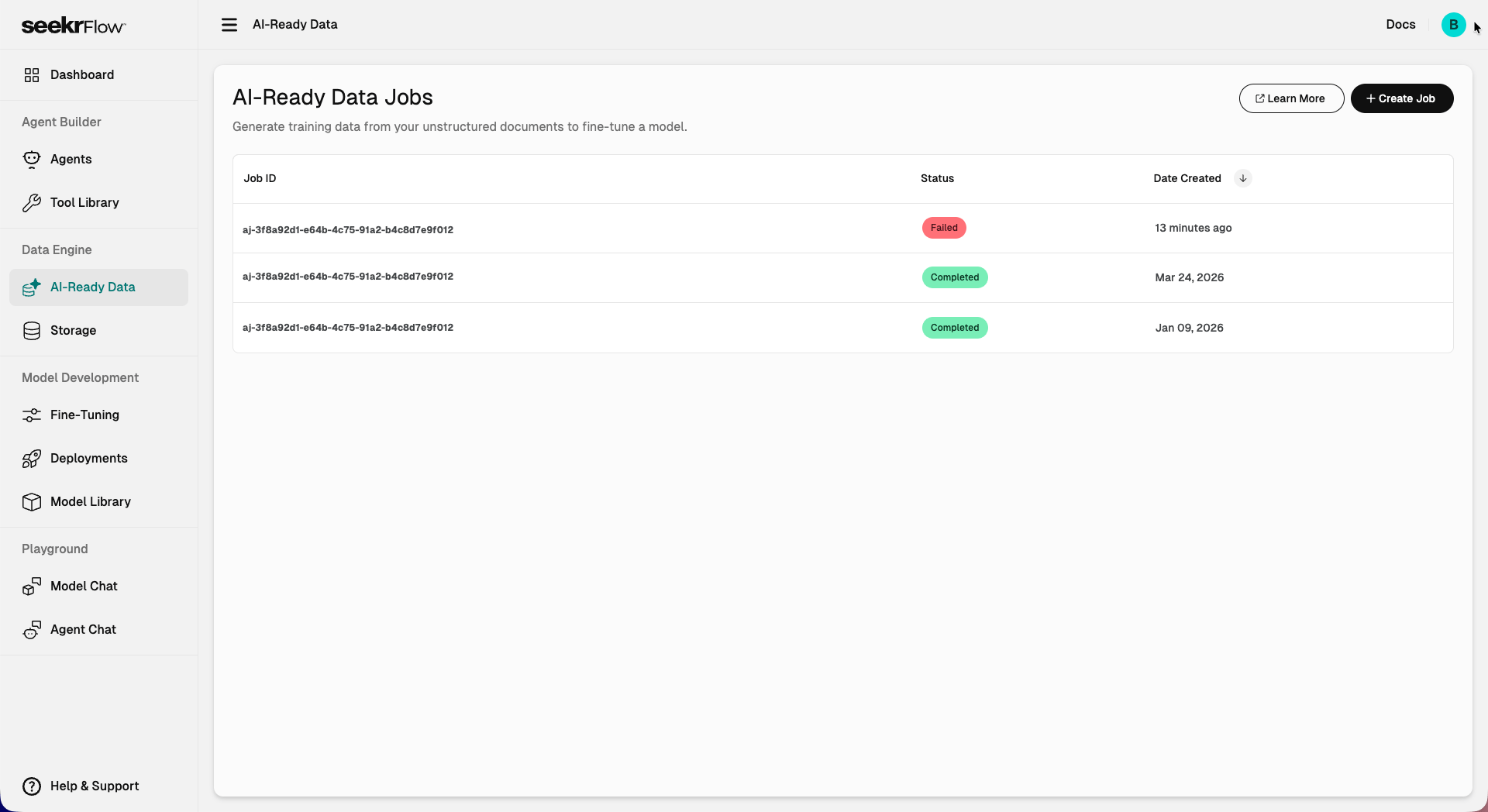
The AI-Ready Data page lists your data generation jobs and their current status. Each job processes your uploaded documents and generates a training dataset you can use to fine-tune a model.
 ## Create an AI-Ready Data job
Navigate to **Data Engine > AI-Ready Data**.
Click **+ Create Job**.
In the **Define Goal and Upload Data Sources** step:
* Enter your fine-tuning goal. Describe the outcome you want to achieve with your fine-tuned model. For example: "I'm developing a chat assistant that must align with the ethical standards and organizational values of my company brand."
* Upload your data source files. Drag and drop or click **Browse**. You can upload up to 10 files at a time. Accepted file formats: PDF, Word, Markdown, JSON. Maximum size 100 MB per file.
Click **Next** to review your setup.
On the **Confirm and Start Job** page, review your fine-tuning goal and data sources, then click **Start Job**.
**Ingestion mode**
AI-Ready Data jobs always use speed-optimized ingestion. To use accuracy-optimized ingestion, use the SDK instead.
## Job status
Each job moves through the following states:
| Status | Description |
| --------- | ------------------------------------------------------------------ |
| Queued | Job is in line to start |
| Running | Documents are being processed and training data is being generated |
| Completed | Training data has been generated and is ready to use |
| Failed | Something went wrong — review your files and try again |
## Output
Once a job completes, the generated training dataset is automatically saved to:
* The **AI-Ready Data** page
* **Data Engine > Storage**
No download is required. When creating a fine-tuning job, you can select the dataset directly from your saved files in SeekrFlow.
## Next steps
* [Create a fine-tuning job](/flow/app/fine-tuning) – Use your generated dataset to train a model
* [Storage](/flow/app/storage) – View and manage your files and generated outputs
## Create an AI-Ready Data job
Navigate to **Data Engine > AI-Ready Data**.
Click **+ Create Job**.
In the **Define Goal and Upload Data Sources** step:
* Enter your fine-tuning goal. Describe the outcome you want to achieve with your fine-tuned model. For example: "I'm developing a chat assistant that must align with the ethical standards and organizational values of my company brand."
* Upload your data source files. Drag and drop or click **Browse**. You can upload up to 10 files at a time. Accepted file formats: PDF, Word, Markdown, JSON. Maximum size 100 MB per file.
Click **Next** to review your setup.
On the **Confirm and Start Job** page, review your fine-tuning goal and data sources, then click **Start Job**.
**Ingestion mode**
AI-Ready Data jobs always use speed-optimized ingestion. To use accuracy-optimized ingestion, use the SDK instead.
## Job status
Each job moves through the following states:
| Status | Description |
| --------- | ------------------------------------------------------------------ |
| Queued | Job is in line to start |
| Running | Documents are being processed and training data is being generated |
| Completed | Training data has been generated and is ready to use |
| Failed | Something went wrong — review your files and try again |
## Output
Once a job completes, the generated training dataset is automatically saved to:
* The **AI-Ready Data** page
* **Data Engine > Storage**
No download is required. When creating a fine-tuning job, you can select the dataset directly from your saved files in SeekrFlow.
## Next steps
* [Create a fine-tuning job](/flow/app/fine-tuning) – Use your generated dataset to train a model
* [Storage](/flow/app/storage) – View and manage your files and generated outputs